Dev Lab#
1. ServiceScope — AI Dependency Mapper#
Focus: AI-Assisted Dependency Analysis & Blast-Radius Modeling Stack: FastAPI, Celery, PostgreSQL, LLM Integration
Summary: An AI-native platform designed to model the “Blast Radius” of code changes. It replaces manual reasoning with machine-assisted dependency intelligence.
▶ View System Architecture & Design
The Problem: The “Implicit Dependency” Trap#
In large microservice ecosystems, dependencies are often implicit (dynamic calls, shared config), undocumented, and tribal. This makes impact analysis slow and error-prone. Engineers cannot answer the fundamental question: “If I change this component, what breaks?”
The Solution#
ServiceScope is a multi-tenant, AI-native system designed to model the “Blast Radius” of code changes. It replaces manual reasoning with machine-assisted dependency intelligence.
System Architecture#
The platform utilizes a fully asynchronous, event-driven pipeline:
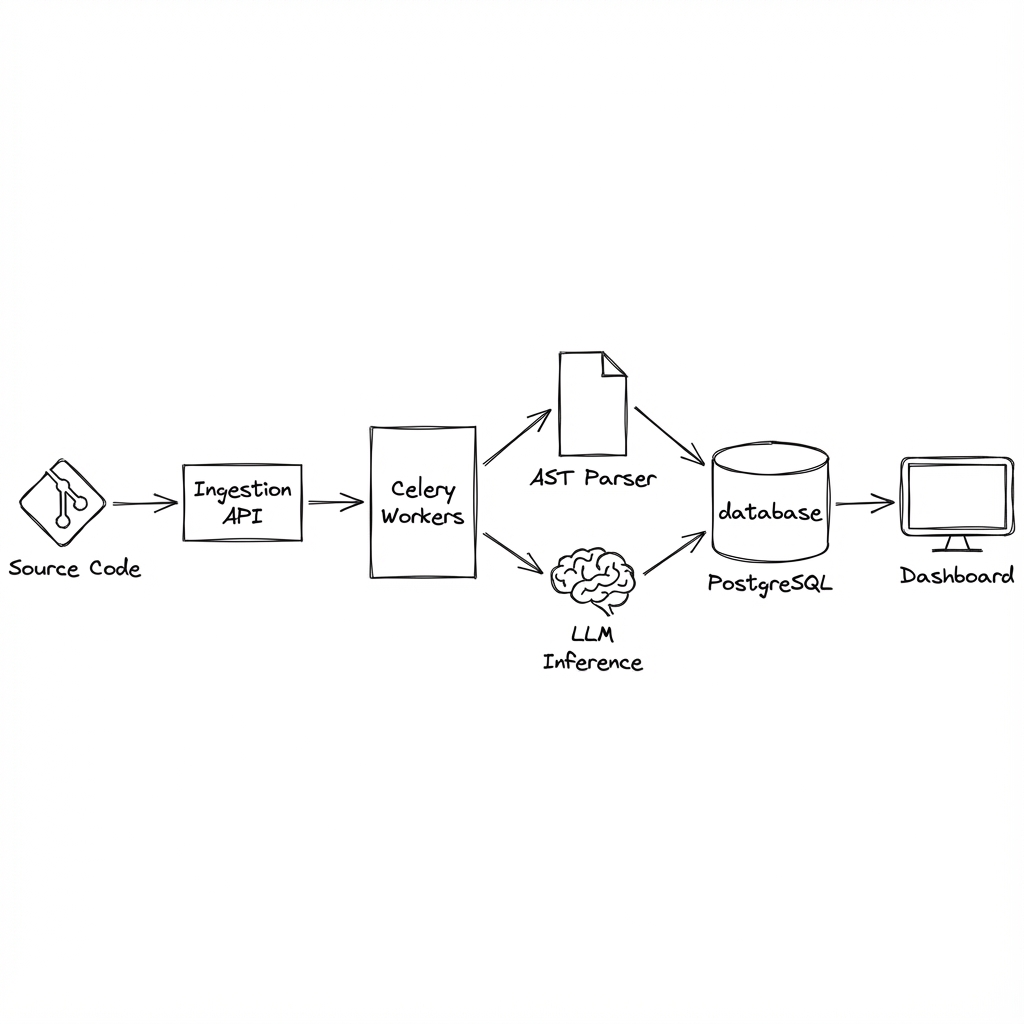
Key Design Decisions:
- Ingestion Plane: Incremental indexing to avoid reprocessing unchanged code.
- Intelligence Engine: Hybrid approach combining static analysis (AST) with LLM inference for semantic understanding.
- Real-Time Graphing: Continuous graph updates for instant upstream/downstream analysis.
2. Adaptive Compute Orchestrator (ACO)#
Focus: Predictive Scheduling for Heterogeneous Compute Stack: Python, GPU/CUDA, Distributed Systems
Summary: A mission-critical scheduler for heterogeneous environments (CPU, GPU, ARM64) that shifts from reactive allocation to predictive, intent-aware orchestration.
▶ View System Architecture & Design
The Concept#
Traditional schedulers treat workloads as opaque units. ACO treats workloads as profiles with intent.
Core Architecture#
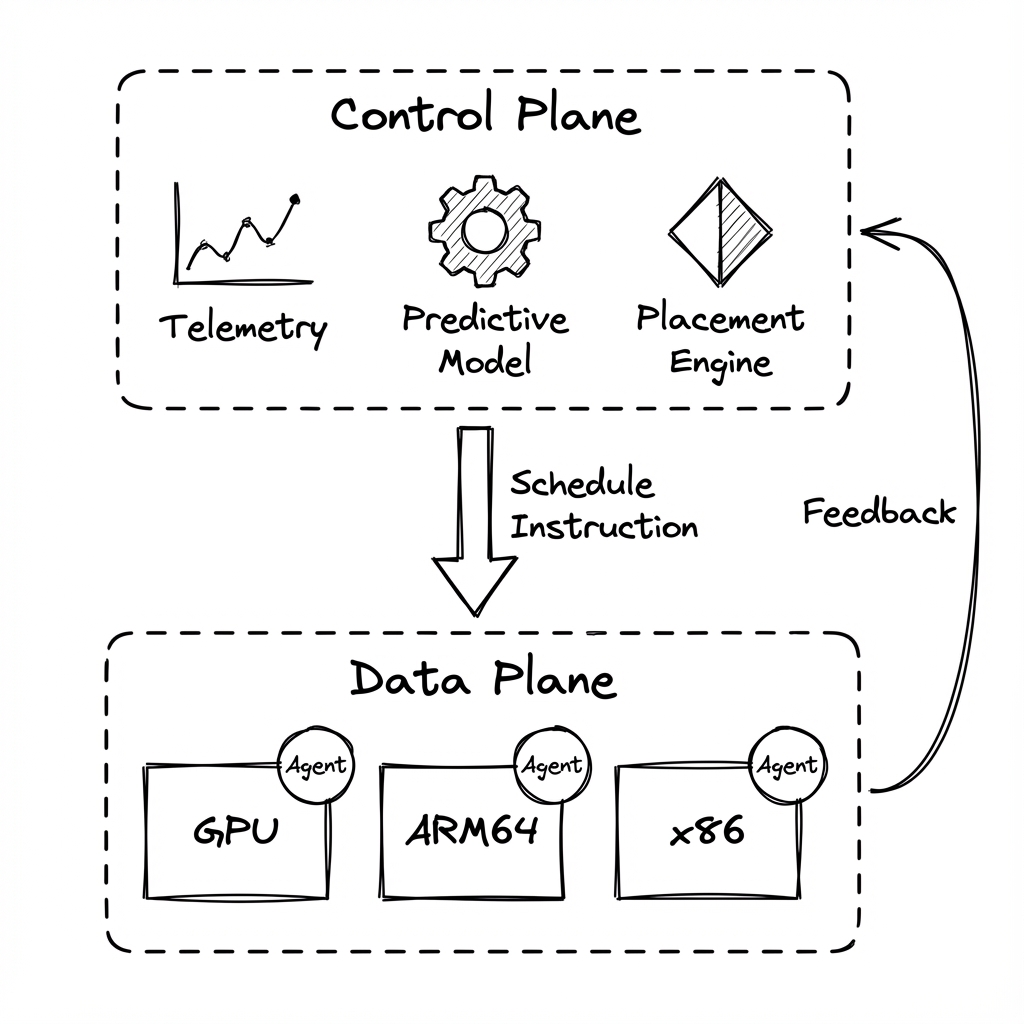
1. Intelligent Control Plane#
- Predictive Modeling: Time-series models forecast workload spikes using historical telemetry.
- Cost-Aware logic: Balances performance targets (SLA) against power and spot-instance pricing.
2. High-Throughput Data Plane#
- Sub-millisecond Decisions: Optimized for extreme concurrency.
- Lightweight Agents: No heavy hypervisors; raw execution on bare metal or lightweight containers.
- Dynamic Bin-Packing: Maximizes hardware utilization across NVIDIA GPUs and x86_64 nodes.
Performance & Impact#
- <10ms end-to-end scheduling latency.
- 28% improvement in resource efficiency via predictive scaling.
- 95%+ SLA adherence during burst workloads.